University of Cambridge · Gonville & Caius College
Suchir Salhan
PhD Candidate in Computer Science · Head of Research at PicoLM
I work on cognitively-inspired multilingual AI and small language models — human-scale, data-efficient language modelling and the interpretability and learning dynamics of small LMs. Supervised by Prof. Paula Buttery.

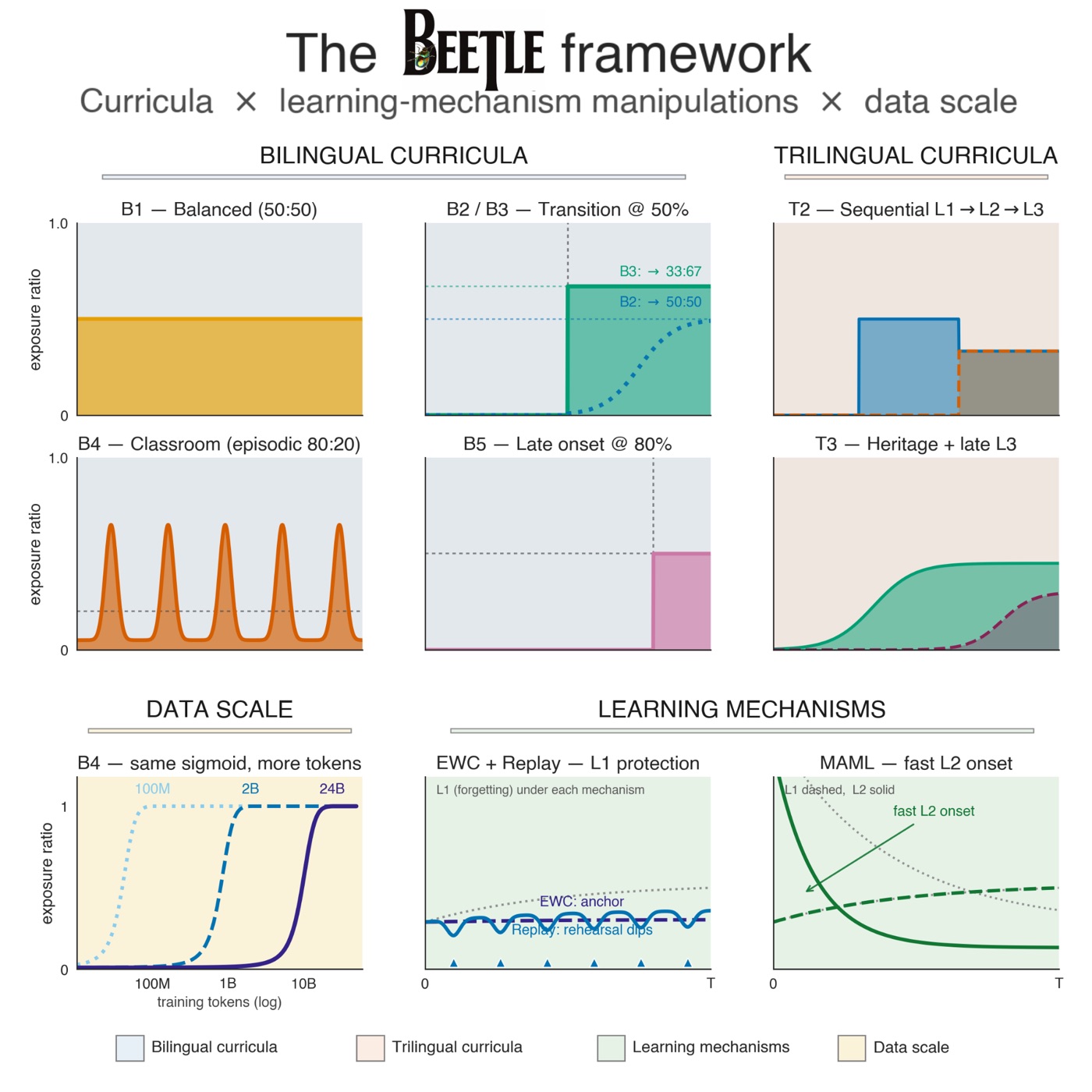
Beetle
An open-source framework I designed and built for controlled bilingual & multilingual pretraining and interpretability. I trained 114 language models across 13 typologically-diverse first languages, 5 exposure curricula and 3 data scales — small Beetle models rival multilingual LLMs up to 8B parameters on human L2 reading-time.
Language models as learners, not just speakers
Much of machine learning is organised around endpoints — benchmarks, leaderboards, final accuracy. I approach language models instead as epistemic artefacts, focusing on learning dynamics rather than end states and drawing on tools from psychometrics and developmental psychology. Small language models are not merely scaled-down versions of larger ones — their value lies in what they make intelligible.
My work spans three strands: learning dynamics & tokenization, cognitively-inspired multilingual AI, and linguistics & cognitive science.
Explore my researchResearch Themes
- Cognitively-Inspired Design & Evaluation — developmentally plausible models & evaluation.
- Pretraining & Interpretability — learning dynamics of small LMs via Pico.
- Multilinguality — human-scale, cross-lingual, bilingual competence via Beetle.
- Tokenization — information-driven subword segmentation (ByteSpan).
- Alignment & Interaction — pedagogical alignment, student proxies.
- Cognitive Science & Linguistics — grammar induction, cross-lingual phonology.
Selected work
~26 peer-reviewed papers & preprints, including two Outstanding Paper Awards at BabyLM 2025. All publications →
Teaching & Supervision
Guest lecturer for L95 — Natural Language Syntax & Parsing (MPhil ACS) and Li18 Computational Linguistics; supervisor across CST IA, IB & II; and lead of the 2025 Small Language Models UROP, built on Pico.
Teaching & resourcesInvited Talks & Seminars
- Language & Multimodal Processing Group, University of Copenhagen — 2026
- Sheffield NLP — Human-Scale AI Frontier — 2026
- 13th Mental Lexicon Conference, McGill University — Invited Keynote — 2025
Collaborators & Students
I work with researchers across the Cambridge PicoLM team, the Cambridge NLIP Group, the ALTA Institute, KAIST AI / NAVER Cloud, and the Language Technology Lab — and supervise MPhil and undergraduate students in Computer Science and Linguistics.
Essays & Reflections
On research, journalism, and academic life.
Year One of a Cambridge PhD
Eight papers, one framework, and a lot of coffee — reflections on the first year.
AcademicPhonology at Home: Hosting OCP23 at Caius
What phonology has to teach AI, and on being a host to ~150 phonologists.
JournalismThree Years of Per Capita Media
What student journalism taught me about independence.
Latest
Get in touch
I welcome enquiries related to my research and am happy to discuss potential projects with current and prospective students. I may have limited availability at certain times of year, but will do my best to respond to all enquiries.